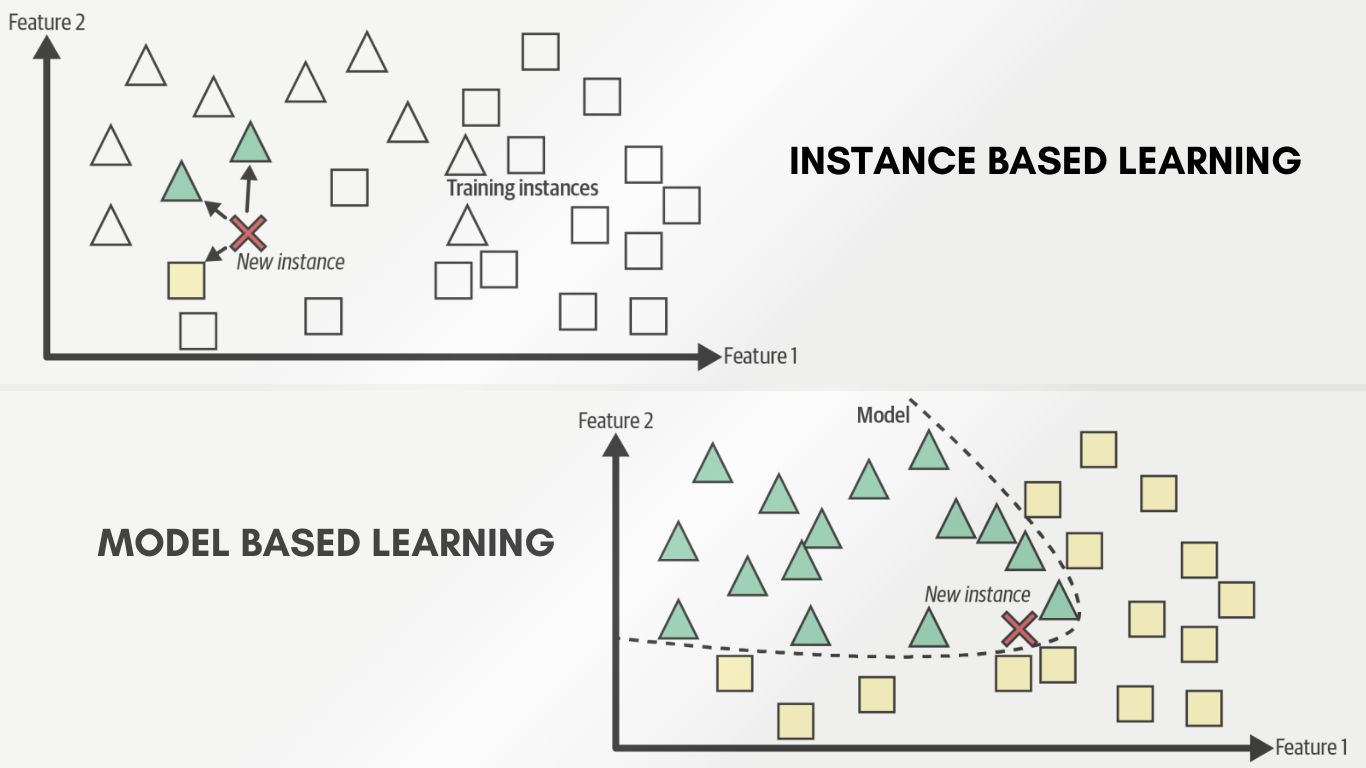
Machine learning, the driving force behind many modern AI applications, encompasses various methodologies. Among these, instance-based learning and model-based learning represent distinct approaches, each with its own strengths and applications. Understanding the differences between these paradigms is crucial for effective problem-solving in machine learning.
Instance-Based Learning: Learning by Example
Instance-based learning, often referred to as memory-based learning, relies on storing and comparing instances of training data to make predictions for new data points. It memorizes the entire training dataset and uses it directly during the prediction phase.
Key Aspects
- Lazy Learning: Instance-based learning is a form of lazy learning as it postpones generalizing from the training data until a new instance needs to be classified or predicted.
- Similarity Measures: It relies on similarity measures (e.g., Euclidean distance, cosine similarity) to find the most similar instances in the training set to make predictions for new instances.
- Low Training Time: Since instance-based learning doesn’t involve explicit training, the training phase itself is quick. The computational load occurs during prediction.
Applications
- K-Nearest Neighbors (KNN): Used in recommendation systems, classification tasks, and regression problems where instances close to new data points are crucial for predictions.
- Anomaly Detection: Detecting outliers or anomalies in data where the focus is on identifying instances significantly different from the majority.
- Imputation of Missing Values: Predicting missing values by identifying similar instances with available data.
- Collaborative Filtering: Powering recommendation systems by finding similar users or items based on their interactions or characteristics.
- Text Categorization: Classifying text documents based on similarity measures and nearest neighbor techniques.
- Clustering: Applied in clustering algorithms to group similar instances together, such as in hierarchical clustering or DBSCAN.
Example Scenario: Predicting Patient Disease Risk
Instance-Based Learning (K-Nearest Neighbors – KNN)
Imagine a healthcare system employing instance-based learning, specifically KNN, to predict a patient’s risk of developing a certain disease based on historical patient data.
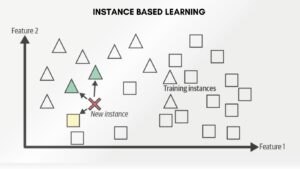
- Instance-Based Approach: In KNN, the system retains a dataset of patient records containing attributes like age, BMI, blood pressure, and cholesterol levels, along with their corresponding disease outcomes (e.g., whether they developed the disease or not).
- Prediction Process: When a new patient arrives, the system identifies the ‘k’ most similar patients (based on attributes) from the stored dataset.
- Prediction: The prediction for the new patient is based on the majority outcome of the ‘k’ similar patients. If most of the similar patients had the disease, the system predicts a higher risk for the new patient.
- Example: Suppose a new patient, John, is 45 years old, has a high BMI, and elevated blood pressure. The system identifies five similar patients from the dataset with similar attributes. As four out of five similar patients had the disease, the system predicts a high risk of the disease for John.
Model-Based Learning: Generalizing Patterns
In contrast, model-based learning focuses on building a generalized model from the training data. Instead of storing the entire dataset, it captures the underlying patterns and relationships to make predictions for new instances.
Key Aspects
- Generalization: Model-based learning aims to generalize patterns from the training data to make predictions for unseen instances, often using algorithms like decision trees, neural networks, or linear regression.
- Explicit Training Phase: Model-based learning involves an explicit training phase where the model learns the patterns and relationships from the data, adjusting its parameters iteratively.
- Higher Training Time: The training phase in model-based learning can be computationally intensive as it involves building and optimizing a model based on the dataset.
Applications
- Predictive Analytics: Used extensively in forecasting future trends, making predictions in financial markets, demand forecasting, and weather predictions.
- Medical Diagnosis: Building models to diagnose diseases based on learned patterns and relationships from medical data.
- Natural Language Processing (NLP): Employed in sentiment analysis, language translation, and speech recognition tasks where understanding underlying structures is crucial.
- Image and Object Recognition: Utilized in computer vision tasks like image classification, object detection, and facial recognition by extracting intricate patterns and features.
- Fraud Detection: Identifying fraudulent activities in banking or insurance sectors by recognizing unusual patterns and behaviors in transactions.
- Optimization and Control Systems: Modeling complex systems to optimize processes or control systems based on learned relationships and parameters.
Example Scenario: Predicting Patient Disease Risk
Model-Based Learning (Logistic Regression)
Now, consider the healthcare system using a model-based approach, such as logistic regression, to predict disease risk.
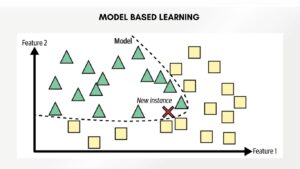
- Model Building: The system analyzes the historical patient dataset, discerning patterns and relationships between various patient attributes and disease outcomes.
- Training the Model: Using logistic regression, the system learns the coefficients and relationships between the patient attributes (e.g., age, BMI, blood pressure) and the likelihood of developing the disease.
- Prediction Process: When a new patient arrives, the system utilizes the learned model’s coefficients to calculate the probability of the new patient developing the disease based on their attributes.
- Example: For a new patient, Sarah, aged 38 with a moderate BMI and normal blood pressure, the system applies the learned coefficients to predict the probability of her developing the disease, offering a percentage likelihood.
Choosing between Instance-Based and Model-Based Learning
The choice between instance-based and model-based learning hinges on several factors:
- Data Size: Instance-based learning can be computationally expensive for large datasets due to its reliance on stored instances, while model-based learning may generalize better.
- Data Complexity: For complex data with nonlinear relationships, model-based learning may outperform instance-based learning, which relies on similarity measures.
- Computational Resources: Instance-based learning might be preferred when computational resources for training models are limited.
Conclusion
Instance-based learning excels in scenarios where similarity-based predictions are effective, whereas model-based learning generalizes patterns for diverse applications. Understanding their characteristics empowers data scientists to choose the most suitable approach based on the nature of the data and the specific requirements of the problem at hand. Integrating the strengths of both approaches can lead to more robust and accurate machine learning solutions.