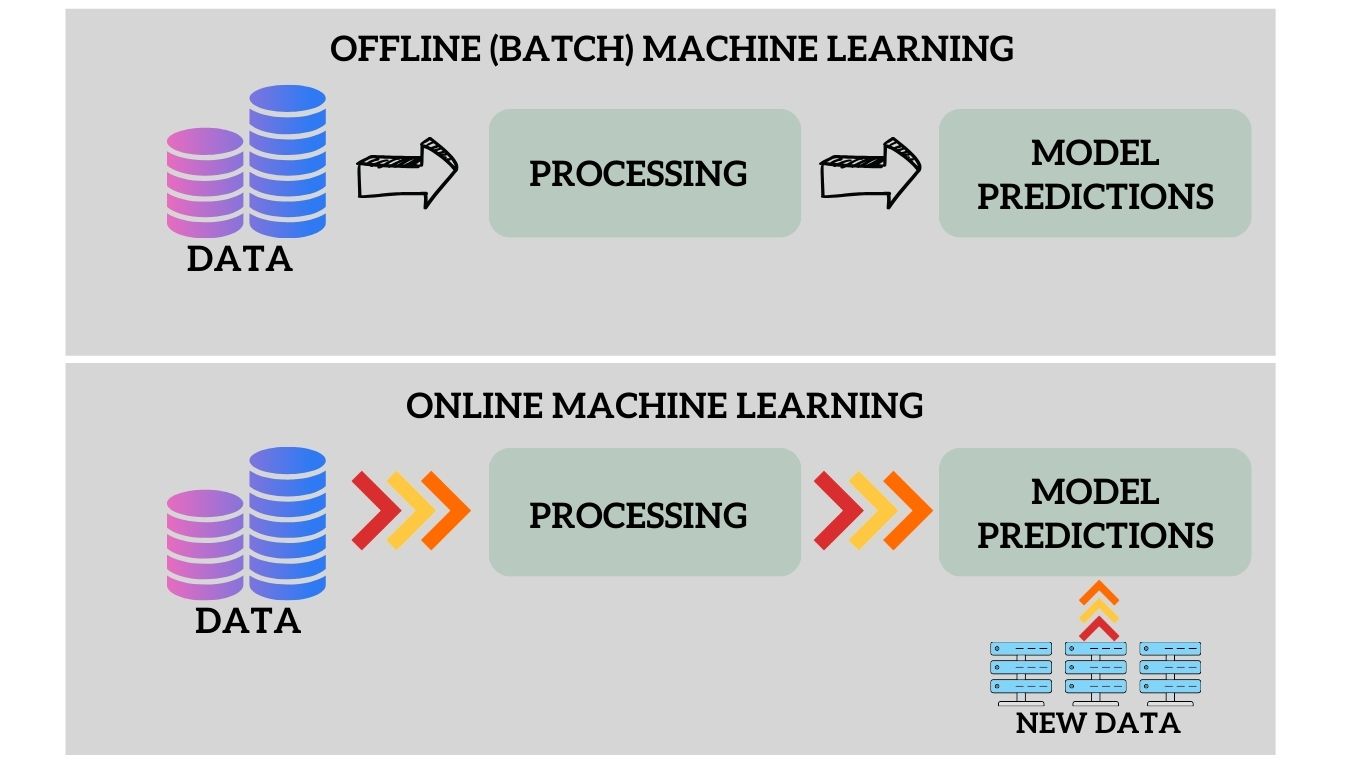
Machine learning, the backbone of artificial intelligence, encompasses diverse methodologies to teach computers to learn patterns from data. Two fundamental approaches, offline vs online machine learning, form the bedrock of machine learning models. Understanding their nuances is crucial for crafting effective learning strategies for various applications.
Offline (Batch) Machine Learning
In offline or batch machine learning, the model is trained on a static dataset that is available beforehand. The entire training process occurs independently of any real-time data streams. This approach is typical in scenarios where the dataset is fixed or periodically updated, but the model’s training doesn’t incorporate data arriving in real-time. After training, the model is deployed to make predictions or perform tasks on new, unseen data.
Advantages
1. Stable Learning: Analyzing the entire dataset allows models to capture complex patterns comprehensively.
2. Optimized Resource Utilization: By processing data in bulk, batch learning can leverage parallel computing, optimizing resource usage.
3. Consistency: As the model trains on fixed data, results are consistent across iterations.
Limitations
1. Scalability Challenges: Large datasets may strain memory and computational resources, hindering scalability.
2. Inflexibility to New Data: Once trained, models cannot adapt to new information without retraining on the entire dataset.
Applications
Image Recognition, Natural Language Processing (NLP), Recommendation Systems, Fraud Detection or anything related to Machine Learning where data patterns remain constant without sudden concept drifts.
Online Machine Learning
Contrary to offline (batch) learning, online learning or incremental learning, embraces a dynamic approach. Online machine learning involves continuously updating the model as new data becomes available. The model learns incrementally from incoming data, often in a streaming fashion. This approach is used when the data arrives continuously or in real-time, and the model needs to adapt to changing patterns or trends. Online learning enables the model to evolve and improve its predictions as it encounters new information.
Advantages
1. Real-Time Adaptability: Continuous learning allows models to adapt to changing data patterns in real-time.
2. Resource Efficiency: Online learning conserves resources by processing data incrementally, suitable for large, streaming datasets.
3. Adaptive to Evolving Trends: The model remains relevant and adaptable to evolving trends and patterns.
Limitations
1. Sensitivity to Noise: Incremental updates may lead to overfitting or sensitivity to noisy data.
2. Inability to Revisit Past Data: Once processed, data instances are usually discarded, limiting the ability to relearn from previous experiences.
Applications
Adaptive Personalization, Dynamic Pricing, IoT and Sensor Data Analysis, Healthcare Monitoring, finance, economics where new data patterns are constantly emerging.
Choosing the Right Approach
Selecting between batch and online learning hinges on various factors:
- Data Dynamics: For static datasets, batch learning suffices. For continuously evolving data, online learning is more suitable.
- Resource Constraints: Consider computational resources and memory limitations; batch learning may be challenging for large datasets.
- Real-Time Adaptation: Applications requiring immediate adaptation to changing data patterns benefit from online learning.
The choice between offline (batch) and online learning rests on the nature of the data, computational resources, and the need for real-time adaptation. While batch learning provides stability and thorough analysis, online learning excels in adapting to dynamic data environments. Understanding their strengths and limitations empowers data scientists to employ the most fitting methodology for their machine learning endeavors.