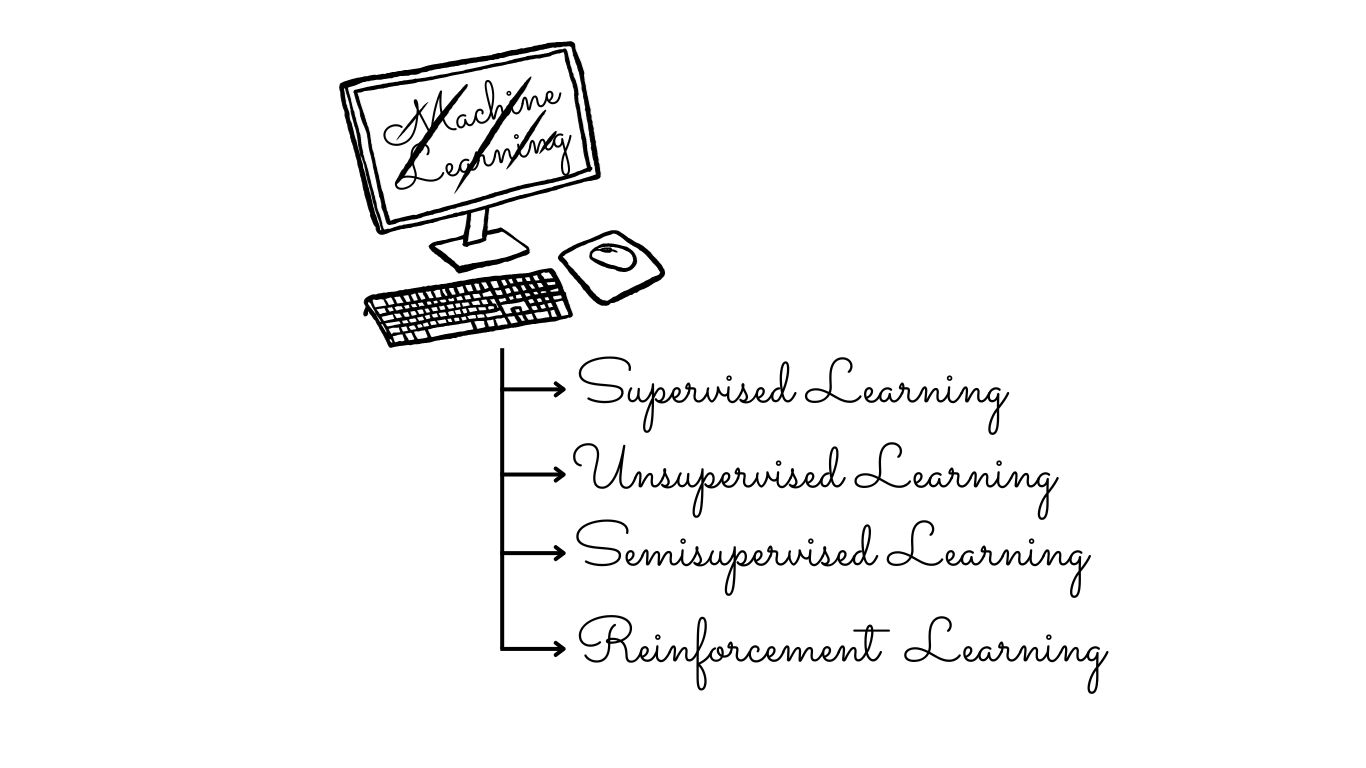
Machine Learning can be categorized based on the level and nature of supervision provided during the training process. Generally, there exist four primary types of machine learning approaches.
Supervised Learning
In the realm of machine learning, supervised learning stands as a cornerstone method, essential for teaching algorithms to discern patterns and make predictions or classifications. Its functionality revolves around training models using labeled datasets, where the algorithm learns from the provided data to make informed decisions.
Supervised learning delves into two primary tasks: regression and classification. These tasks find extensive application in various domains, from filtering spam emails to predicting stock prices. But how does supervised learning work in practice?
Let’s consider a scenario where we have a dataset containing information on 5000 students. This dataset includes columns for IQ, CGPA, and Job Placement, where the latter is dependent on the former two columns. This forms the basis of a supervised learning problem, where the machine learning algorithm’s objective is to establish a relationship between the input columns (IQ and CGPA) and the output column (Job Placement).
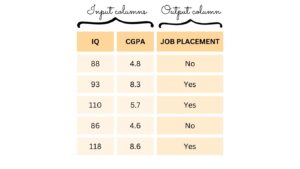
Data in supervised learning typically falls into two categories: numerical and categorical. Numerical data encompasses attributes like age, weight, IQ, and CGPA, while categorical data consists of attributes like gender, nationality, and binary values (Yes/No).
Regression vs. Classification – The classification of supervised learning problems is contingent upon the nature of the output column. If the output column is numerical, it falls under the category of a regression problem. In contrast, when the output column is categorical, the supervised learning problem is termed a classification problem.
The essence of supervised learning lies in its ability to generalize from known data to predict outcomes for new, unseen data. By training on labeled datasets, the algorithm learns patterns and relationships, enabling it to make accurate predictions or classifications when presented with new input.
Unsupervised Learning
In the vast landscape of machine learning, unsupervised learning stands as a compelling counterpart to its supervised counterpart. Unlike supervised learning, unsupervised learning dives into the realm of unlabeled data, aiming to unravel underlying patterns or structures within it. It’s like solving a puzzle without knowing the final picture—exciting and challenging.
Picture this: we’re presented with a dataset void of the familiar output column seen in supervised learning. We’re in the dark about what exactly needs predicting or classifying. However, armed with this raw, untouched data, unsupervised learning steps in and works its magic, opening up a world of possibilities.

The Four Types of Unsupervised Learning
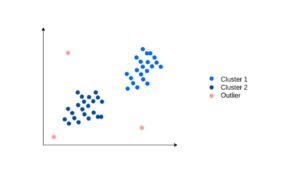
1. Clustering: Think of clustering as the art of grouping similar things together. This algorithm slices and dices the data into clusters based on similarities. Imagine plotting the above data and discovering three distinct categories:
-
- Students with high CGPA and low IQ
- Students with high IQ and low CGPA
- Students with high CGPA and high IQ
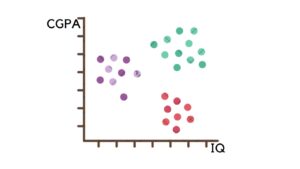
With these newfound categories, we can label the data and apply the powerful tools of supervised learning. And hey, it’s not just limited to 2D data—clustering can handle n-dimensional data and even get into hierarchical clustering.
2. Dimensionality Reduction: Sometimes, less is more. Dimensionality reduction steps in to streamline the dataset by trimming down features without losing the essence of the data. It’s like tidying up your room by merging similar items into one or using PCA to transform the data into a more manageable form, perfect for visualizations.
3. Anomaly Detection and Outlier Analysis: Anomaly detection and outlier analysis employ various statistical, machine learning, and data mining techniques to identify unusual or unexpected patterns, points, or events within a dataset that deviate significantly from the norm or expected behavior. The goal is to distinguish between regular behavior and exceptional cases to either address potential issues or gain valuable insights from the unusual data points. For instance, in cybersecurity, anomaly detection helps identify potential threats by spotting unusual patterns in network traffic.
4. Association Rule Mining: Ever noticed how certain things go hand in hand? Association rule mining is all about uncovering these intriguing relationships in large datasets. It’s like peeking into a retail store’s sales data and realizing that customers who buy bread are highly likely to grab a carton of milk too. These rules help unveil hidden connections among variables, providing valuable insights into consumer behavior.
Semi-Supervised Learning
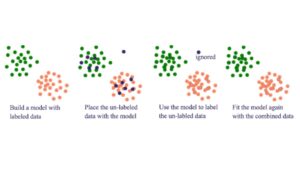
Semi-supervised learning stands at the intersection of supervised and unsupervised learning, harnessing the power of both labeled and unlabeled data. In this approach, the algorithm learns from a small amount of labeled data and a more extensive pool of unlabeled data to make predictions or classifications. By leveraging the labeled data’s guidance and the vast untapped potential of unlabeled data, semi-supervised learning strives to improve the model’s accuracy and generalization. This hybrid method often proves beneficial in scenarios where obtaining labeled data is costly or time-consuming, allowing for more efficient and effective utilization of available resources in the realm of machine learning.
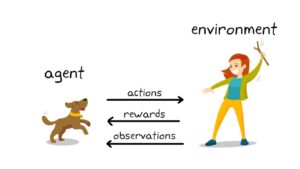
Reinforcement Learning
Reinforcement learning is a dynamic branch of machine learning that draws inspiration from how humans learn through trial and error. In this approach, an agent interacts with an environment, taking actions to achieve specific goals while receiving feedback in the form of rewards or penalties based on its actions. Through this continuous interaction, the agent learns optimal strategies or policies to maximize cumulative rewards over time. Reinforcement learning finds applications in diverse fields, from training AI in games and robotics to optimizing complex decision-making processes in areas like finance and healthcare. Its ability to learn from experience and adapt to changing environments makes it a powerful tool for solving problems where explicit instructions or labeled data might be unavailable.